




SORT. Some pieces of TDF are
LABELs, some are TAGs, some are
ERROR_TREATMENTs and so on (to list some of the more
transparently named SORTs). The SORTs of
the arguments and result of each construct of the TDF format are specified.
For instance, plus is defined to have three arguments - an
ERROR_TREATMENT and two EXPs (short for
"expression") - and to produce an EXP;
goto has a single LABEL argument and produces
an
EXP. The specification of the SORTs of the
arguments and results of each construct constitutes the syntax of
the TDF format. When TDF is represented as a parsed tree it is structured
according to this syntax. When it is constructed and read it is in
terms of this syntax.
The structure of capsules is designed so that the process of linking
two or more capsules consists almost entirely of copying large byte-aligned
sections of the source files into the destination file, without changing
or even examining these sections. Only a small amount of interface
information has to be modified and this is made easily accessible.
The translation process only requires an extra indirection to account
for this interface information, so it is also fast. The description
of TDF at the capsule level is almost all about the organisation of
the interface information.
There are three major kinds of entity which are used inside a capsule
to name its constituents. The first are called tags; they are used
to name the procedures, functions, values and variables which are
the components of the program. The second are called tokens; they
identify pieces of TDF which can be used for substitution - a little
like macros. The third are the alignment tags, used to name alignments
so that circular types can be described. Because these internal names
are used for linking pieces of TDF together, they are collectively
called linkable entities. The interface information relates
these linkable entities to each other and to the world outside the
capsule.
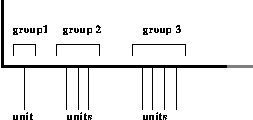
The most important part of a capsule, the part which contains the
real information, consists of a sequence of groups of units. Each
group contains units of the same kind, and all the units of the same
kind are in the same group. The groups always occur in the same order,
though it is not necessary for each kind to be present.
The order is as follows:
The tags and tokens in a capsule have to be related to the outside
world. For example, there might be a tag standing for printf,
used in the appropriate way inside the capsule. When an object file
is produced from the capsule the identifier printf must occur
in it, so that the system linker can associate it with the correct
library procedure. In order to do this, the capsule has a table of
tags at the capsule level, and a set of external links which provide
external names for some of these tags.
In just the same way, there are tables of tokens and alignment tags
at the capsule level, and external links for these as well.
The tags used inside a unit have to be related to these capsule tags,
so that they can be properly named. A similar mechanism is used, with
a table of tags at the unit level, and links between these and the
capsule level tags.
Again the same technique is used for tokens and alignment tags.
It is also necessary for a tag used in one unit to refer to the same
thing as a tag in another unit. To do this a tag at the capsule level
is used, which may or may not have an external link.
The same technique is used for tokens and alignment tags.
So when the TDF linker is joining two capsules, it has to perform
the following tasks:
During the process of installation the values associated with the
linkable entities can be accessed by indexing into an array followed
by one indirection. These are the kinds of object which in a programming
language are referred to by using identifiers, which involves using
hash tables for access. This is an example of a general principle
of the design of TDF; speed is required in the linking and installing
processes, if necessary at the expense of time in the production of
TDF.
A typical token definition has parameters from various
A typical use of this token is:
There is no way of obtaining anything like a side-effect. A token
without parameters is therefore just a constant.
Tokens can be used for various purposes. They are used to make the
TDF shorter by using tokens for commonly used constructions (ptr_add
is an example of this use). They are used to make target dependent
substitutions (~char in the use of ptr_add is an example
of this, since ~char may be signed or unsigned on the target).
A particularly important use is to provide definitions appropriate
to the translation of a particular language. Another is to abstract
those features which differ from one ABI to another. This kind of
use requires that sets of tokens should be standardised for these
purposes, since otherwise there will be a proliferation of such definitions.
First, as part of the evolution of TDF, new features will from time
to time be identified. It is highly desirable that these can be added
without disturbing the current encoding, so that old TDF can still
be installed by systems which recognise the new constructions. Such
changes should only be made infrequently and with great care, for
stability reasons, but nevertheless they must be allowed for in the
design.
Second, it may be required to add extra information to TDF to permit
special processing. TDF is a way of describing programs and it clearly
may be used for other reasons than portability and distribution. In
these uses it may be necessary to add extra information which is closely
integrated with the program. Diagnostics and profiling can serve as
examples. In these cases the extra kinds of information may not have
been allowed for in the TDF encoding.
Some extension mechanisms are described below and related to these
reasons:
If a new kind of unit is added, it can contain any information, but
if it is to refer to the tags and tokens of other units it must use
the linkable entities. Since new kinds of unit might need extra kinds
of linkable entity, a method for adding these is also provided. All
this works in a uniform way, with capsule level tables of the new
entities, and external and internal links for them.
If new kinds of unit are added, the order of groups must be the same
in any capsules which are linked together. As an example of the use
of this kind of extension, the diagnostic information is introduced
in just this way. It uses two extra kinds of unit and one extra kind
of linkable entity. The extra units need to refer to the tags in the
other units, since these are the object of the diagnostic information.
This mechanism can be used for both purposes.
Part of the TenDRA Web.2.1. The Overall Structure
A separable piece of TDF is called a CAPSULE.
A producer generates a CAPSULE; the TDF linker links
CAPSULEs together to form a CAPSULE; and
the final translation process turns a CAPSULE into an
object file.
This organisation is imposed to help installers, by ensuring that
the information needed to process a unit has been provided before
that unit arrives. For example, the token definitions occur before
any tag definition, so that, during translation, the tokens may be
expanded as the tag definitions are being read (in a capsule which
is ready for translation all tokens used must be defined, but this
need not apply to an arbitrary capsule).



This can be done without looking into the interior of the units (except
for the tld unit), simply copying the units into their new
place.
2.2. Tokens
Tokens are used (applied) in the TDF at the point where
substitutions are to be made. Token definitions provide the substitutions
and usually reside on the target machine and are linked in there.
SORTs and produces a result of a given SORT.
As an example of a simple token definition, written here in a C-like
notation, consider the following.
EXP ptr_add (EXP par0, EXP par1, SHAPE par2)
{
add_to_ptr(
par0,
offset_mult(
offset_pad(
alignment(par2),
shape_offset(par2)),
par1))
}
This defines the token, ptr_add, to produce something of
SORT EXP. It has three parameters, of
SORTs EXP, EXP and
SHAPE. The add_to_ptr, offset_mult,
offset_pad, alignment and shape_offset
constructions are TDF constructions producing respectively an
EXP, an EXP, an EXP, an
ALIGNMENT and an EXP.
ptr_add(
obtain_tag(tag41),
contents(integer(~signed_int), obtain_tag(tag62)),
integer(~char))
The effect of this use is to produce the TDF of the definition with
par0, par1 and par2 substituted by the actual
parameters.
2.3. Tags
Tags are used to identify the actual program components. They can
be declared or defined. A declaration gives the SHAPE
of a tag (a SHAPE is the TDF analogue of a type). A definition
gives an EXP for the tag (an EXP describes
how the value is to be made up).
2.4. Extending the format
TDF can be extended for two major reasons.
SORT in TDF can be extended
indefinitely (except for certain auxiliary SORTs). This
mechanism should only be used for extending standard TDF to the next
standard, since otherwise extensions made by different groups of people
might conflict with each other. See Extendable
integer encoding.SORTs) can be supplied. This mechanism should only
be used for the second purpose, though it could be used to experiment
with extensions for future standards. See
BITSTREAM.
Crown
Copyright © 1998.